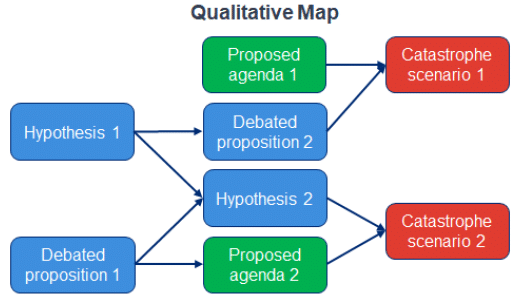
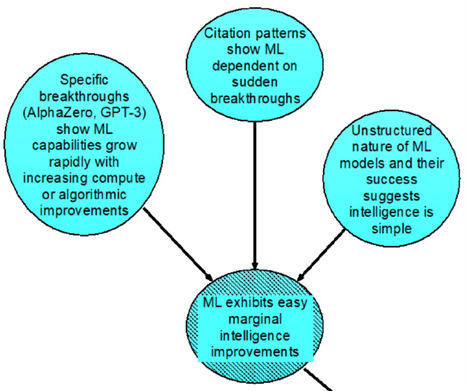
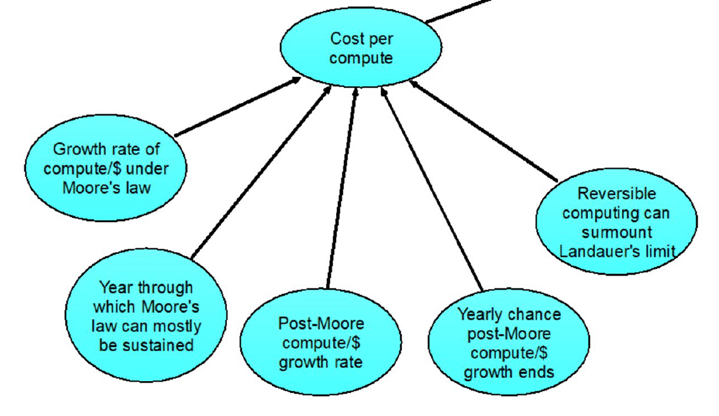
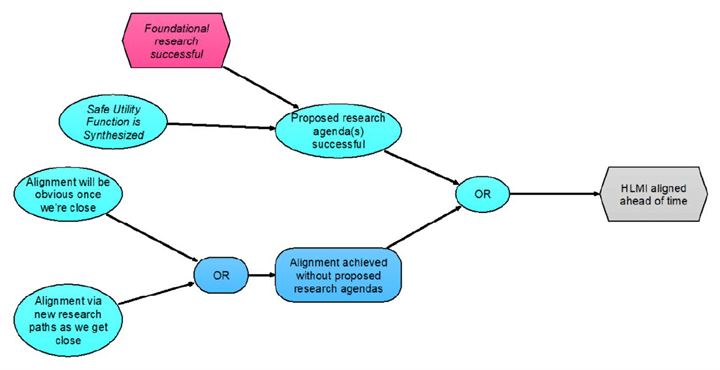
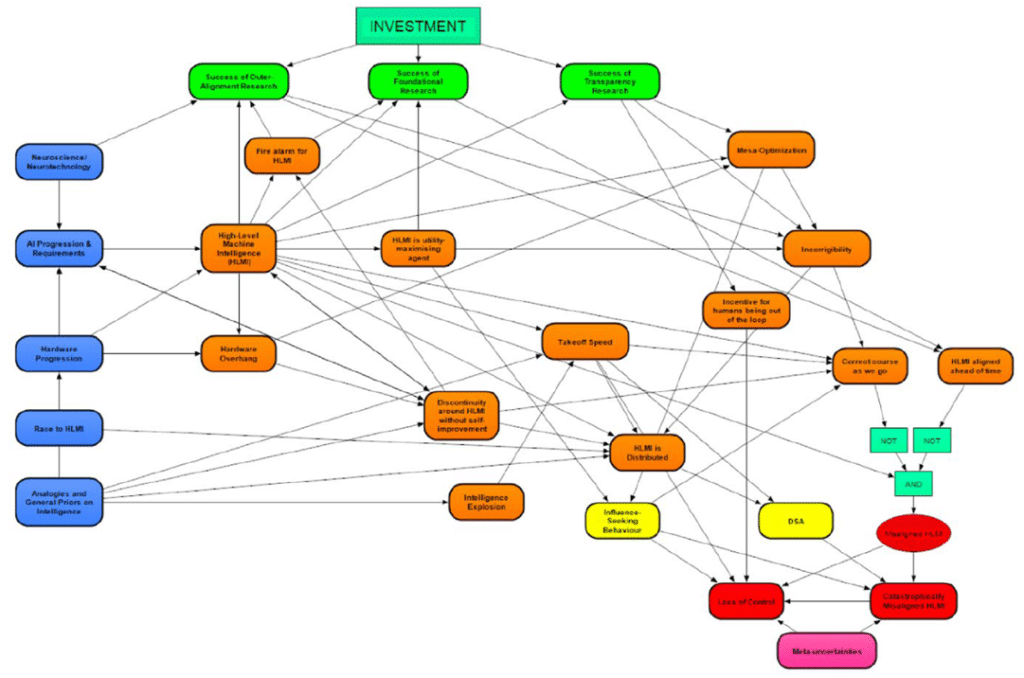
The recent accelerated progress in artificial intelligence (AI) suggests that the prospect of AI exceeding human intelligence is no longer just science fiction. Some AI researchers are seriously worried about whether we’ll be able to keep such advanced AI under human control, and whether it could lead to catastrophic outcomes where AI decides that humans are dispensable. A group of researchers on AI is using Analytica influence diagrams to map out arguments and scenarios to explore what we could do to avoid these risks. They are now attempting to quantify the AI risk and decision analysis with some assistance from Lumina.
The recent accelerated progress in artificial intelligence (AI) suggests that the prospect of AI exceeding human intelligence is no longer just science fiction. Some AI researchers are seriously worried about whether we’ll be able to keep such advanced AI under human control, and whether it could lead to catastrophic outcomes where AI decides that humans are dispensable. A group of researchers on AI is using Analytica influence diagrams to map out arguments and scenarios to explore what we could do to avoid these risks. They are now attempting to quantify the AI risk and decision analysis with some assistance from Lumina.