
Experienced analysts and modelers know that “Oh shit!” moment all too well. You inspect the first results from your new model and they are obviously wrong. They are off by an order of magnitude. Or you change a key assumption, and it has no effect on the result. Or it has a big effect — but in the opposite direction from what you expected. Or it recommends as the best option what you know is a wrong decision.
So you gather your wits and start to dig through the guts of the model to find out what happened. Often it turns out to be a simple mistake – you mistyped a formula, the data has a bad format, or you divided by a conversion constant when you should have multiplied. But sometimes, after exhaustive scrutiny of the model code and the data, and running more sensitivity analyses, you just can’t see anything wrong – at least not in the model. Eventually, it starts to dawn on you. The problem turns out to be a lot more interesting than a mere modeling mistake. It is your intuition that is wrong. As you figure it out, you start to correct your mental model that formed the basis of your intuitive expectations. Finally that “Oh shit” feeling turns into a valuable new insight and a reason to celebrate!
An example: The Bake-Off
Here’s a case from early in my career as a decision analyst. This case also shows why it helps to have a normative framework like decision analysis – instead of treating human expertise and intuition as the “gold standard.”
Back in 1986, I found myself in a heated debate with another (then) young professor, at the second Conference on Uncertainty in Artificial Intelligence (UAI). I was trying to convince him that the best way to treat uncertainty in an expert system or decision support system is to use probability distributions structured in Bayesian belief networks and influence diagrams. (Influence diagrams extend belief networks by adding decisions and objectives to the chance variables.) He replied that natural human reasoning just doesn’t use anything like numerical probabilities or Bayesian inference. So it’s more natural to represent human expertise as a set of if-then rules with heuristic measures of the “strength of evidence”. Such heuristic rule-based expert systems were the basis of the first boom in artificial intelligence in the early 1980s. (The boom ended with a bust, the “AI Winter”, that descended at the end of that decade, as people realized that rule-based systems were not sufficiently scalable.)
The early UAI conferences spawned many such debates. They were founded by researchers (including me) from a range of then-disparate fields, including AI, logic, statistics, decision theory, cognitive psychology, and philosophy. We wanted to clarify and, some hoped, resolve the differences among the many competing schemes for reasoning under uncertainty, including rule-based expert systems, Bayesian belief and causal networks, influence diagrams, fuzzy set theory, nonmonotonic logic, Dempster-Shafer theory, and more. Some of us wanted to find or create an approach that was grounded in a compelling theory of rationality. It also had to be tractable in terms of the human effort to build systems and the computational effort to run them.
To his great credit, my interlocutor was not content to leave our debate a matter of words, or even theorems − unlike too many other participants. He proposed a bake-off: Each of us should build a practical system for the same problem using our preferred methods. We could then compare our approaches and the performance of two systems. He invited me to spend a week with him that summer at his university. He identified a task, the diagnosis and treatment of root disorders in apple trees, and a willing expert, Dr. Daniel R. Cooley, a plant pathologist with ten years’ experience in the domain. US orchardists sold over a billion dollars’ worth of apples per year in the 1980s − and twice that today. Untreated root disorders of apple trees can ruin an orchard − and its owner.
Treating ailing apple trees
We took turns to interview Dr Cooley to encode his domain knowledge. He explained three key afflictions of apple trees − extreme cold during the winter, waterlogged soil, and phytophthora, a fungus-like pathogen. (A related species of phytophthora causes Sudden Oak Death, which plagues oak trees in several parts of the US including my literal backyard in California’s Santa Cruz Mountains.) We each interviewed the expert in our own style. My colleague did “knowledge engineering” to encode the expert’s knowledge as a set of rules. I encoded his knowledge as an influence diagram. Both our models represented the relationships among the causes, symptoms, tests, and treatments for these disorders. This diagram shows some key elements of our two models:
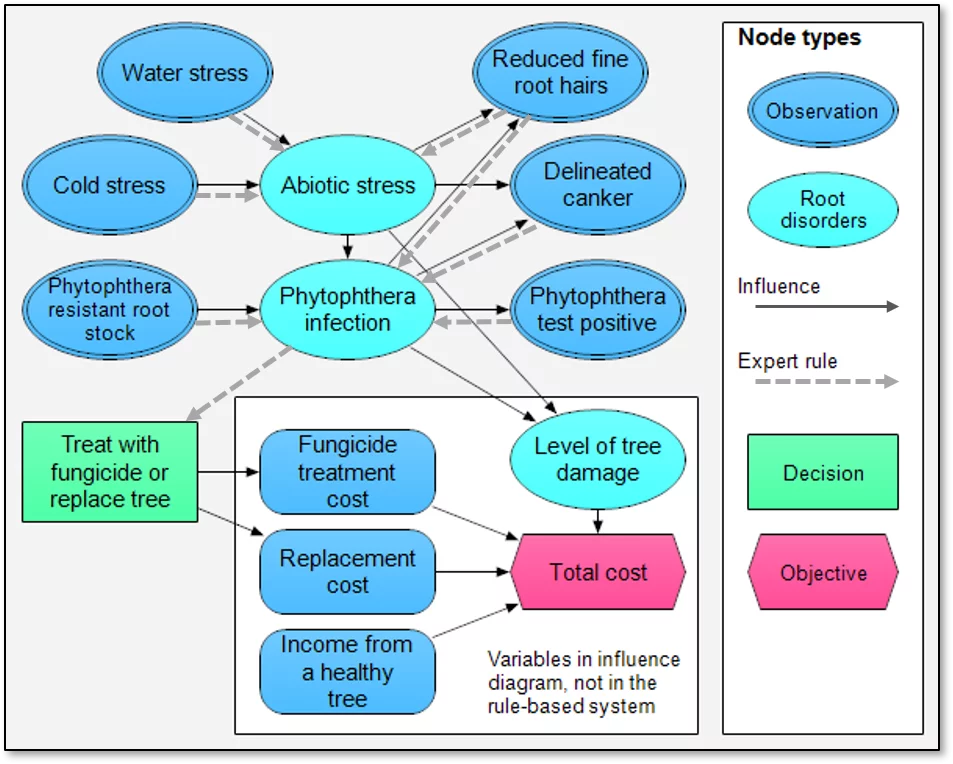
Most of the nodes are common to both systems. The gray dashed arrows depict the rules that my colleague created using the then-popular KEE software from Intellicorp – for example from the observation Phytophthera test positive to the disorder Phytophthera infection:
If {Phytophthera test} is {positive} then {Phytophthera infection} is strongly supported.
The solid black arrows show causal relationships encoded as conditional probability distributions – for example, the probability of Phytophthera test positive conditional on the disorder Phytophthera infection, and conditional on the disorder being absent, i.e. the true and false positive rates:
Pr[Phytophthera test positive| Phytophthera infection] = 90%
Pr[Phytophthera test positive| No Phytophthera infection] = 5%
Note that the dashed arrow depicting the rule goes in the opposite direction to the solid arrow depicting the conditional probabilities. The influence diagram system applies Bayesian inference to “reverse the arrows” and estimate the probability of Phytophthera infection given the observed test result, and all the other observed variables that relate to it.
Dr. Cooley told us that the standard treatment for trees infected by phytophthera is to apply a fungicide, which my colleague encoded as this rule:
If {Phytophthera infection} is {positive} then {Treat with fungicide} is strongly supported.I built the model as an influence diagram model in Demos (the predecessor of Analytica). The influence diagram has more nodes than the rule-based system. It includes the five nodes on the bottom right of the figure above that had no counterpart in the rule-based system. They calculate the objective to minimize Total cost based on the Level of tree damage (based on the two disorders), and the Fungicide treatment cost or Replacement cost, according to the decision to treat or replace the tree. The Total cost also includes the effect of permanent root damage on reducing the Income from a healthy tree. This decision analysis approach recommends Treat with fungicide if that reduces expected Total cost relative to replacing the tree.
Testing and refining the model
The next phase was to test and debug the two systems. This provided an interesting contrast. We applied each system to a set of example cases, each with a set of observations and corresponding recommendation. When the rule-based system suggested a treatment different from the expert’s recommendation, my colleague modified or added rules until it did agree with the expert. For the rule-based system, the expert’s judgment was the gold standard.
Similarly, when the influence diagram model disagreed with the expert – for example, in many cases it recommended tree replacement even when phytophthera was strongly suspected — I carefully checked my model with him to make sure that the influences, probabilities, and costs accurately reflected his considered knowledge and judgment. He confirmed that they did. However, as a decision analyst familiar with the extensive psychological research on the fallibility of human judgment under uncertainty, I did not assume that his inferences and recommendations were necessarily valid. So I then explained to him why the model made recommended against the fungicide: It turns out that its effectiveness is limited because, based on what he had told me, there is a low probability that the tree is both curable – i.e. actually has an infection — and not already so damaged that it will never provide an economic yield of apples. So, it is more cost-effective to just replace the tree with a new seedling. After careful reflection he found this explanation convincing; he added that it should be of great practical value to orchardists who should consider revising their standard protocol for treatment.
When results are ridiculous
When the results of a model appear obviously ridiculous – in conflict with our commonsense intuitions – there are two possible reasons: Most often there’s a mistake in the model. It does not correctly reflect available data, the experts’ knowledge, or the modelers’ intent. In that case, we need to diagnose the bug and fix it.
But sometimes, as in this case of ailing apple trees, the problem is more interesting. As we scrutinize the model, and understand how it generates this unexpected result, we may come to realize that the model is actually correct. It was our intuition that was wrong. We can now revise and improve our intuition to reflect this deeper understanding. It’s time to stop trying to fix sick apple trees with fungicide.
And then it’s time to celebrate! We have learned something new and interesting from the modeling process. In fact, improving our intuition and getting new insights is often the main reason to build models in the first place. If a model always replicated our original expectations, what would be the point of building it in the first place?
Postscript
 The Association for Uncertainty in Artificial Intelligence continues to flourish and had its 34th Conference in Monterey, California in August 2018. It has largely transcended its origins in the “uncertainty wars” among advocates of alternative representations. Most contributors now take for granted the use of probabilistic Bayesian networks, as do modern standard AI textbooks, such as Artificial Intelligence: A Modern Approach by Stuart Russell and Peter Norvig. With the remarkable success of deep-learning in the last decade, a key focus is on automated learning of probabilistic models from massive quantities of data, rather than hand-crafted knowledge engineering of heuristic rules from domain experts. However, decision analysts who focus on helping people make complex decisions with long-term implications cannot rely just on historical data. We continue to work with human experts and decision makers using influence diagrams and probabilities to represent their knowledge, decision options and objectives, often in combination with data-derived models. The synthesis of powerful analytics using statistical and machine learning methods on large amounts of data from the past with decision analysis methods to model client objectives and expert judgments about future uncertainties provides practical value far beyond what is possible from each method alone.
The Association for Uncertainty in Artificial Intelligence continues to flourish and had its 34th Conference in Monterey, California in August 2018. It has largely transcended its origins in the “uncertainty wars” among advocates of alternative representations. Most contributors now take for granted the use of probabilistic Bayesian networks, as do modern standard AI textbooks, such as Artificial Intelligence: A Modern Approach by Stuart Russell and Peter Norvig. With the remarkable success of deep-learning in the last decade, a key focus is on automated learning of probabilistic models from massive quantities of data, rather than hand-crafted knowledge engineering of heuristic rules from domain experts. However, decision analysts who focus on helping people make complex decisions with long-term implications cannot rely just on historical data. We continue to work with human experts and decision makers using influence diagrams and probabilities to represent their knowledge, decision options and objectives, often in combination with data-derived models. The synthesis of powerful analytics using statistical and machine learning methods on large amounts of data from the past with decision analysis methods to model client objectives and expert judgments about future uncertainties provides practical value far beyond what is possible from each method alone.





